我們已經知道,Prompt Warehouse Management (PWM) 是 POG 框架的兩大支柱之一,負責將 prompt 從「原始材料」加工成「高品質資產」。
但這個「加工廠」內部究竟是如何運作的?
成功的 PWM 依賴一套清晰、可重複的流程,確保每一個入庫的 prompt 都符合工程標準。這個流程可以被分解為四個核心階段:發現 (Discovery)、標準化 (Normalization)、驗證 (Validation),以及版本化與倉儲管理 (Versioning & Repository)。
讓我們一步步拆解這個從混亂到秩序的旅程。

目標:識別並收集散落在組織各處、有潛在重用價值的 prompt。
在實施 PWM 的初期,這是一個「尋寶」的過程。你的團隊需要像考古學家一樣,去挖掘那些已經被創造出來、但尚未被管理的 prompt。
這個階段的關鍵是「寧濫勿缺」。先將所有看起來有用的 prompt 收集起來,形成一個「候選池」。這個池子裡的 prompt 可能格式混亂、品質不一,但它們是後續所有工作的基礎。
目標:將非結構化的 prompt 文本,轉化為包含豐富元數據、格式統一的結構化物件。
這是將「原始材料」加工成「半成品」的關鍵步驟。如果沒有標準化,每個 prompt 都是一個黑盒子,無法被有效管理或查詢。
一個標準化的 prompt 物件,除了 prompt 本身,至少應該包含以下元數據:
| 元數據欄位 | 說明 | 範例 |
|---|---|---|
id |
唯一的識別碼 | prompt-user-summary-v1 |
name |
人類可讀的名稱 | 使用者行為摘要 |
description |
描述此 prompt 的用途與目的 | 將使用者的原始活動日誌,摘要成一段簡短的重點描述。 |
version |
版本號,遵循語意化版本 (SemVer) | 1.2.0 |
author |
創建者或維護者 | team-alpha |
tags |
用於分類與搜索的標籤 | summary, user-profile, risk-control |
model_parameters |
適用的模型與參數 | { "model": "gpt-4", "temperature": 0.5 } |
schema |
輸入變數 (inputs) 與輸出格式 (output) 的定義 | inputs: { "user_logs": "string" }, output: "json" |
透過標準化,我們讓 prompt 從一句話,變成了一個可被機器讀取、可被系統理解的「規格說明書」。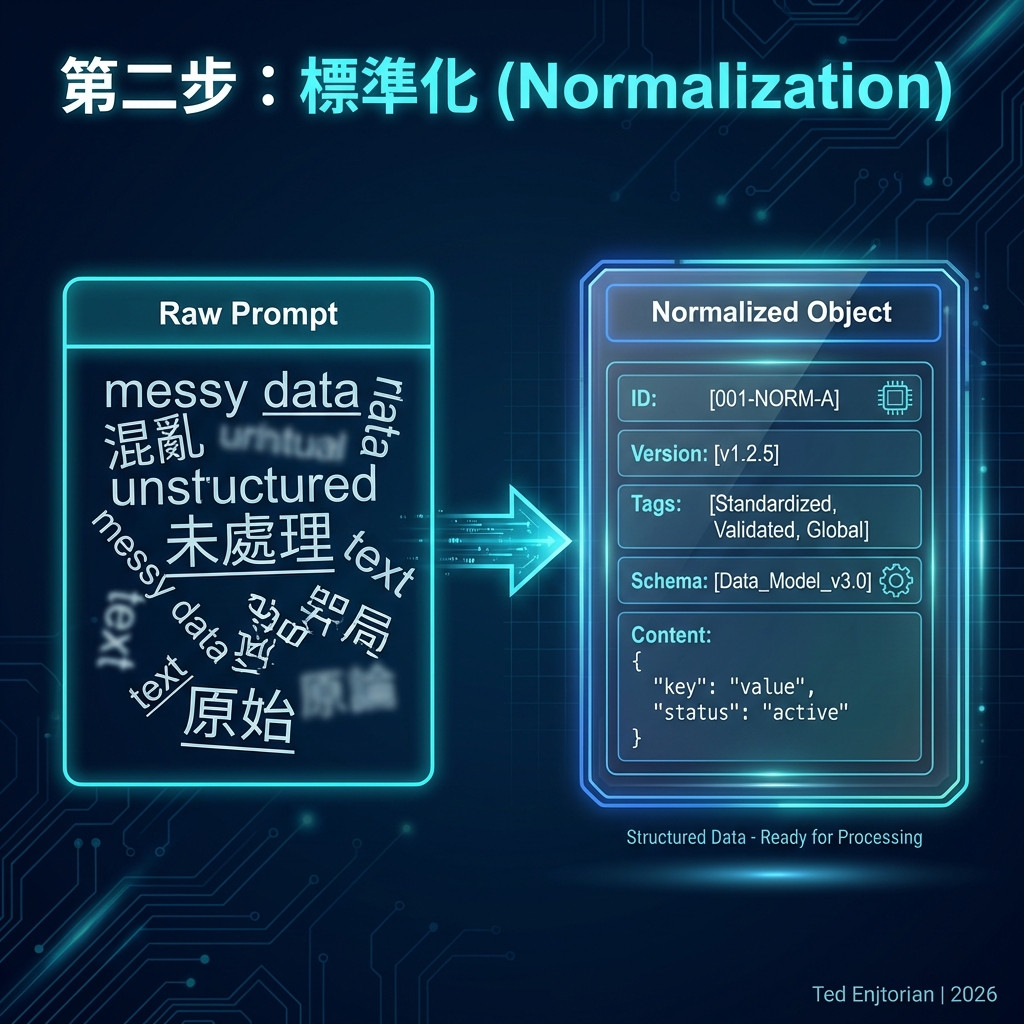
目標:透過一系列自動化或半自動化的測試,確保 prompt 的品質、穩定性、安全性與合規性。
這是 PWM 中最能體現「工程化」思維的一環。一個未經驗證的 prompt,就像一段未經測試的程式碼,隨時可能引發線上問題。
功能驗證 (Functional Validation)
健壯性驗證 (Robustness Validation)
效能驗證 (Performance Validation)
合規與倫理驗證 (Compliance & Ethical Validation)
只有通過了這些驗證門檻的 prompt,才能被視為「可信賴」的資產。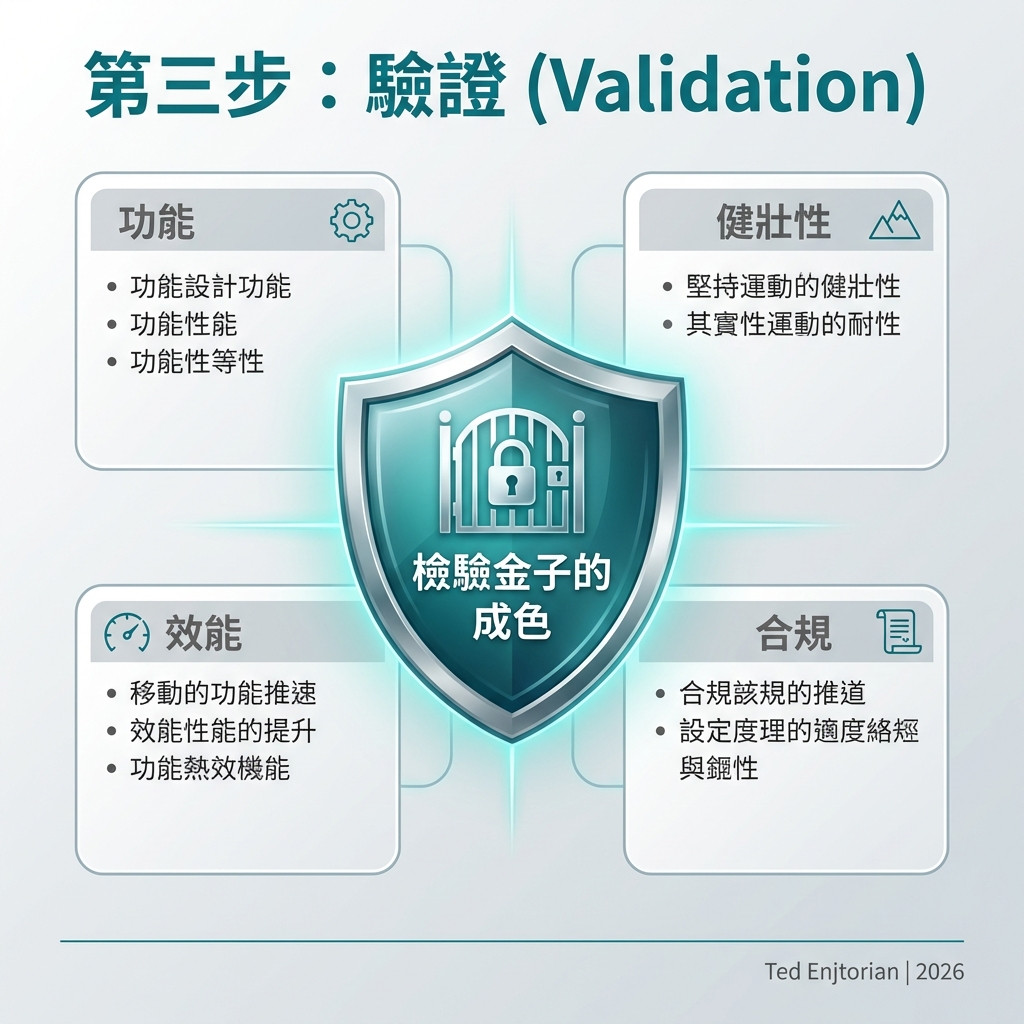
目標:將通過驗證的 prompt 存入一個中央化的 Repository,並對其進行嚴格的版本控制。
這是流程的最後一站,也是 prompt 資產化成果的集中體現。
主版號.次版號.修訂號 (e.g., 2.1.5) 來管理 prompt 的演進。
package.json 一樣,明確依賴某個具體的 prompt 版本。Prompt Warehouse Management 的四個步驟——發現、標準化、驗證、版本化——共同構成了一條從混亂走向秩序的清晰路徑。
它將 prompt 管理從一門「藝術」,轉變為一項可預測、可衡量的「工程學科」。透過這套流程,團隊不僅能夠建立起一個可信的 Prompt 資產庫,更重要的是,能夠在組織內部建立起一種對品質、穩定與協作負責的文化。
在下一篇文章中,我們將探討 POG 的另一大支柱:
Prompt Library 如何與 SDLC 整合? 看看這些存放在倉庫裡的珍貴資產,是如何在開發前線發揮最大價值的。
最完整的內容 : https://enjtorian.github.io/prompt-orchestration-governance-whitepaper/zh-tw/
 enjtorian
enjtorian

 iThome鐵人賽
iThome鐵人賽